Learn AI
This article takes you through my experience with learning how to use different AI tools. Detailing how the project started, my experience with it and the surprising transferable skills gained.
Key Summary
AI and quantum computing are set to reshape our world, similar to how the internet did. Learning these skills now really can give you a significant advantage in the job market and in developing new ideas.
Key AI concepts like Machine Learning, Large Language Models, and Natural Language Processing are all linked.
The training process for Large Language Models like ChatGPT involves massive
datasets, parameter adjustments, and iterative improvements, leading to increasingly efficient and accurate language processing.The Transformer architecture, which powers ChatGPT, uses mechanisms like tokenisation, embedding, and self-attention layers to understand and generate human-like text
It understands the relationship between words but also it's place within a sentence which
There are various AI tools available such as Perplexity for research, Merlin for summarising, and ChatGPT for creating bots.
How the project started
AI has become a bit of a buzz word in recent times. It seems that all companies are pivoting to release new AI assisted features at a rate no one could foresee. But what is AI and how can you use it? I'm of the belief that AI and quantum will be the two next major technological advancements that will reshape the wold as we know it. Similar to the creation of the internet, If you are ahead of the curve and can learn these skills you will have a significant advantage both in the job market but also in creation of new ideas.
AI Glossary
When talking about AI there are a few other terms that also come up. Before jumping in, it's important to understand their differences and how they overlap:
Artificial Intelligence (AI): is the field of computer science focused on creating systems that can perform tasks typically requiring human intelligence. It encompasses various approaches to simulate cognitive functions like learning, problem-solving, and decision-making.
Machine Learning: A subset of AI that enables systems to learn and improve from experience without explicit programming. ML algorithms use statistical techniques to find patterns in data and make predictions or decisions.
Large Language Models: Advanced AI systems trained on vast amounts of text data to understand and generate human-like language. They can perform a wide range of language tasks, from translation to text generation. Chat GTP is an example of this.
Generative AI: AI systems capable of creating new content, such as images, text, or music, based on patterns learned from training data. These models can produce original outputs that mimic human-created content.
Quantum Computing: A computing paradigm that leverages quantum mechanical phenomena to perform certain calculations exponentially faster than classical computers. It has the potential to revolutionise fields such as cryptography (code breaking) and complex system simulations (virtual + safe 'what if' scenarios) .
Natural Language Processing (NLP): A branch of AI focused on enabling computers to understand, interpret, and generate human language. NLP powers applications like machine translation, sentiment analysis, and chatbots.
Automation: The use of technology to perform tasks with minimal human intervention. It often involves AI and machine learning to improve efficiency, accuracy, and scalability in various processes and industries.
Open AI: is a parent research organisation that develops open source technologies (ie the code can be adapted/ used by anyone) to advance artificial intelligence in a safe way. Chat GPT is a product that was developed by Open AI, to generate human like text in response to prompts.
Neural Network: In computer terms this is a machine learning system that allows data and information to be processed to solve complex problems. It does this through pattern recognition, decision making and learning from feedback.
The first hurdle of this project, where to begin? There are so many use cases, it's difficult to whittle down what's actually useful and what will be redundant soon.
What is AI?
The field of Artificial intelligence (AI) came about as a way to process complex datasets and solve problems quicker. This newly found capability of machines, particularly computer systems, to perform tasks that would have typically required human intelligence is what we now deem to be AI.
In recent years, ChatGPT has become synonymous with the term AI. This advanced large language model (LLM) was developed by OpenAI one of the largest and well funded research organisations.
ChatGPT is built upon a specific advanced neural network architecture called the transformer architecture, which is a specialised for processing sequential data, such as text.
Advanced Neuronal Networks (ANN)
By using a similar way to how we process information in the brain, whereby synapses transfer information from one neuron to another. Chat GPT uses a digital version of this called an Advanced Neuronal Network (ANN)
The input layer is the raw data that enters the system from the outside world and then linked by the weighted connections which also contain a parameter value, which indicates to the computer how closely a words meaning (or semantic value) is to the other.
The darker the blue the more negative the number and the more purple the more positive the number.
Using this system you can solve a lot of complex problems.
It's essentially the basis of deep learning as it allows the computer to also learn from it's surroundings, as it independently assigns weight and meaning to different words + structures in a way similar to the human brain.
Advanced Neural Network
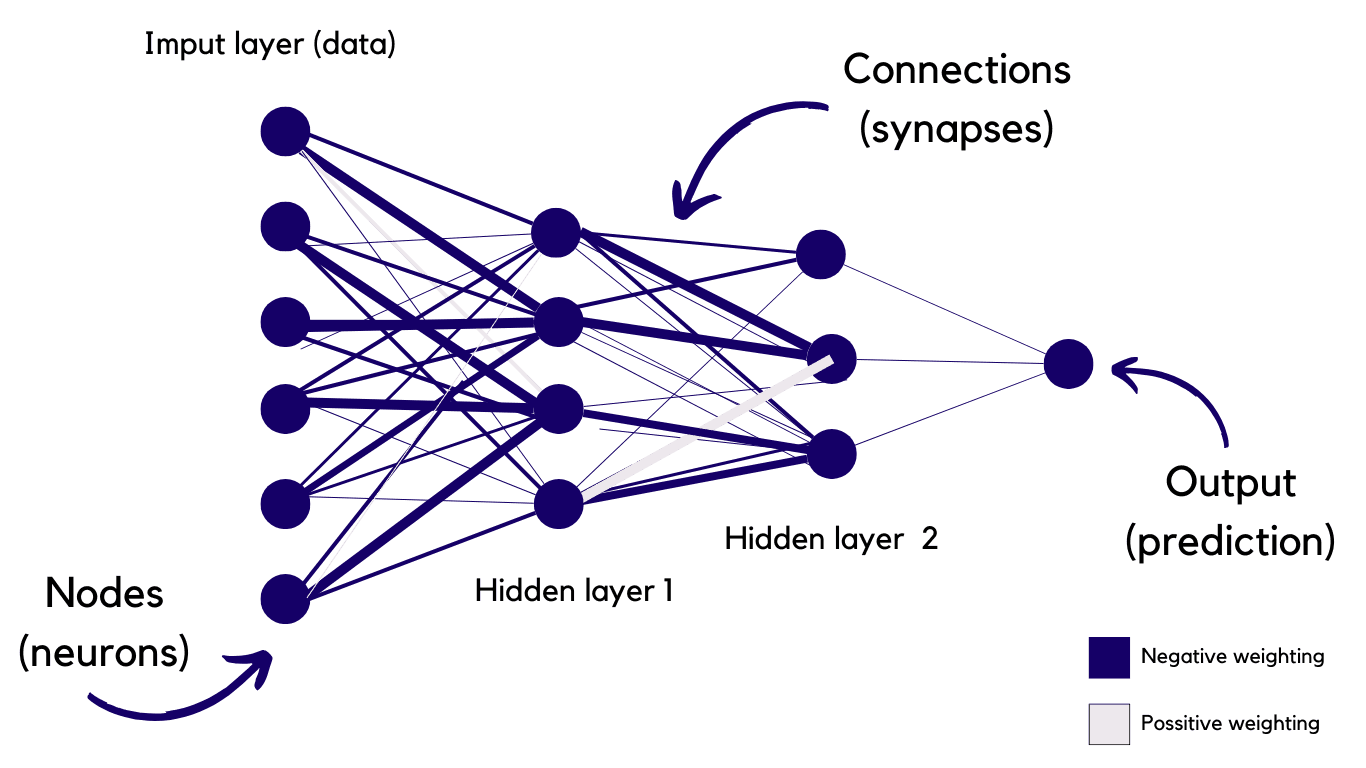
The larger the dataset is (input layer) the larger the memory is needed to access all the information. Each new release of Chat GPT has a vast increase in the amount of data used to train it which is why it can be seen as more intelligent. It's intelligence is directly proportional to the number of parameters ie connections between the nodes (often also referred to as edges) .
How to train a large language model (LLM)
Step 1: Input data such as text form the internet, books and songs etc is added to the system. For example:
The cat sat on the mat.
Step 2: The LLM is set with initial random parameters which has an assigned value. In this example they are all set to 1, There are billions if not trillions of different parameters:
Parameter 1 = 1
Parameter 2 = 1
Parameter 3 = 1
etc
Step 3: The model guesses the next word (also known as a token)
❌ The cat sat on the apple.
❌ The cat sat on the door.
✅ The cat sat on the mat.
Step 4: The model then calculates the word it predicted and the one it should have predicted, mathematically quantifying what the most effective guess would have been probabilistically.
Step 5: Using this information it then auto-adjusts the parameters so that next time the word is used in that context it will be even more precise meaning the model gets progressively more efficient.
Parameter 1 = 1.6
Parameter 2 = -53
Parameter 3 = 1
Chat GPT
The GPT part stands for Generative pre trainer transformer. To most, like me, this probably won't mean much so let's break it down:
Generative: it's intended output is to generate new content ie. text, image, audio etc
Pre-trained: The AI model was previously trained on data
Transformer: This is the architecture in which the data is processed by to create the new generative content
The Transformer:
This diagram takes us through the the steps of a transformer and explains how the 'intelligence' is actualised. This was the biggest breakthrough in making chat GPT possible.
I'll break down the concept from bottom to top.
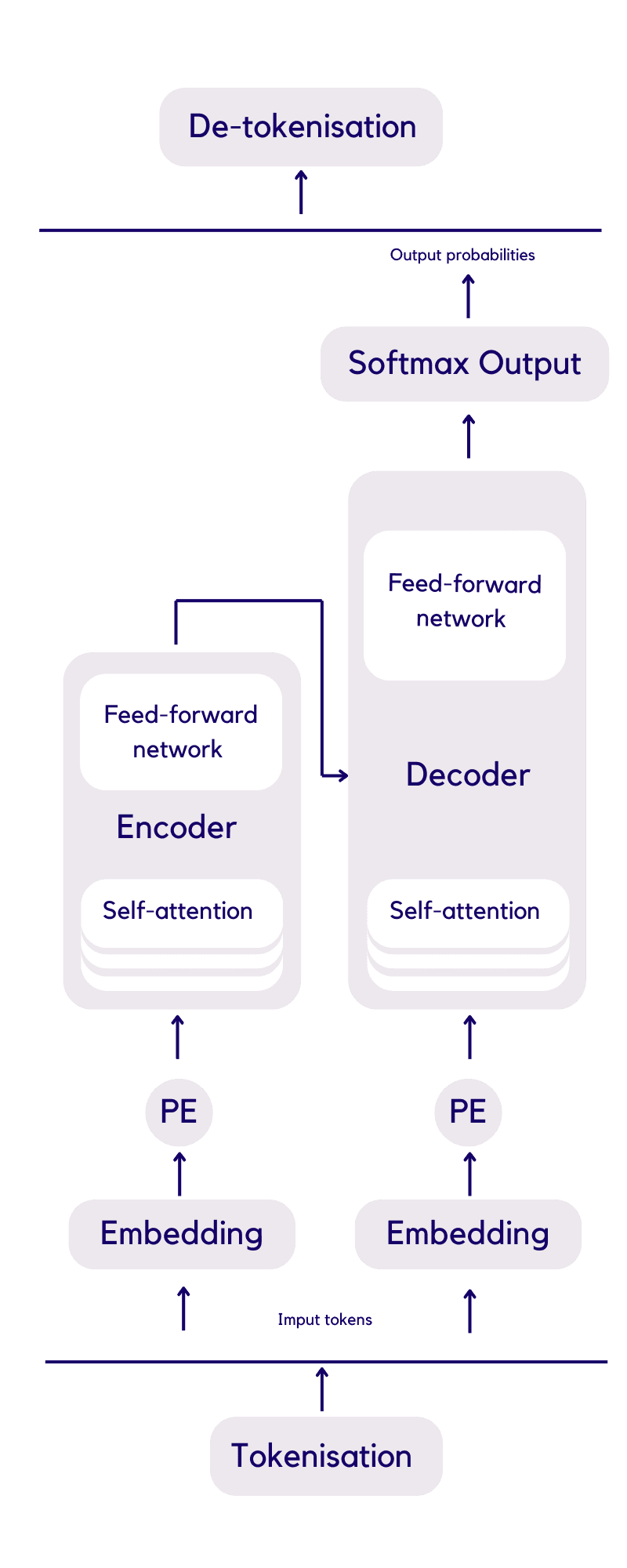
The transformer sits between 2 layers, tokenisation and de-tokenisation.
Step 1: Tokenisation
All forms of a word are first assigned a unique number called a Token ID. This means that the mathematical computer model can understand and interpret the data in a numerical form.
Did you know For each grammatical variation of a word (ie apostrophes and capital letters) a new token will assigned.
Once a word has been assigned it's token ID it's static and that number will be used to represent that word from that point onwards.
So using my example from above the token IDs would be:

Step 2: Embedding
It's now time to convert the token IDs into a high-dimensional vector. This numerical fingerprint allows the number to be plotted. We use the term high-dimensional as there are many hundreds of dimensions ( +co-ordinates) that attribute to each word to it's place in space. As humans this far supersedes our maximum 3D conception of what space is, so these numbers can only truly be mapped by a computer.
In creating these vectors Chat GPT can now understand the way in which words relate to each other. For example; Fish and fisherman are more related in meaning than ball and wind. These fixed coordinates help to indicate strong semantic similarities depending on how closely the words sit to each other. By subtracting the coordinates/ vectors of each word you then get given a figure. This indicates how similar these two words are. Allowing the computer to mathematically understand our language.

Step 3: Positional embedding (PE)
So like token embedding which recognises how close a word is in semantic meaning to one another, positional embedding takes a look at the wider sentence structure. Using form fancy maths it can identify where each word in a prompt sits, relative to all of the other words. Which allows it to understand context.
By understanding the position of the word and the context the translation process is much more precise than out previous attempts at direct language translations (ie Greek to English) .
Final Input embedding:
This is the sum of the token embedding and the positional embedding. These are then fed into the self-attention layer.
Step 4: Self attention layer
This layer assigns a numerical weight to each word, relative to how it relates to every other word. So in the example below The and cat have the heaviest weighted line as 'The' is the proposition to 'cat' therefore a strong connection is shown,

This doesn't just happen once it happens multiple times using different parameters ie. words that rhyme, parameters based on activities performed, peoples relationships etc etc.
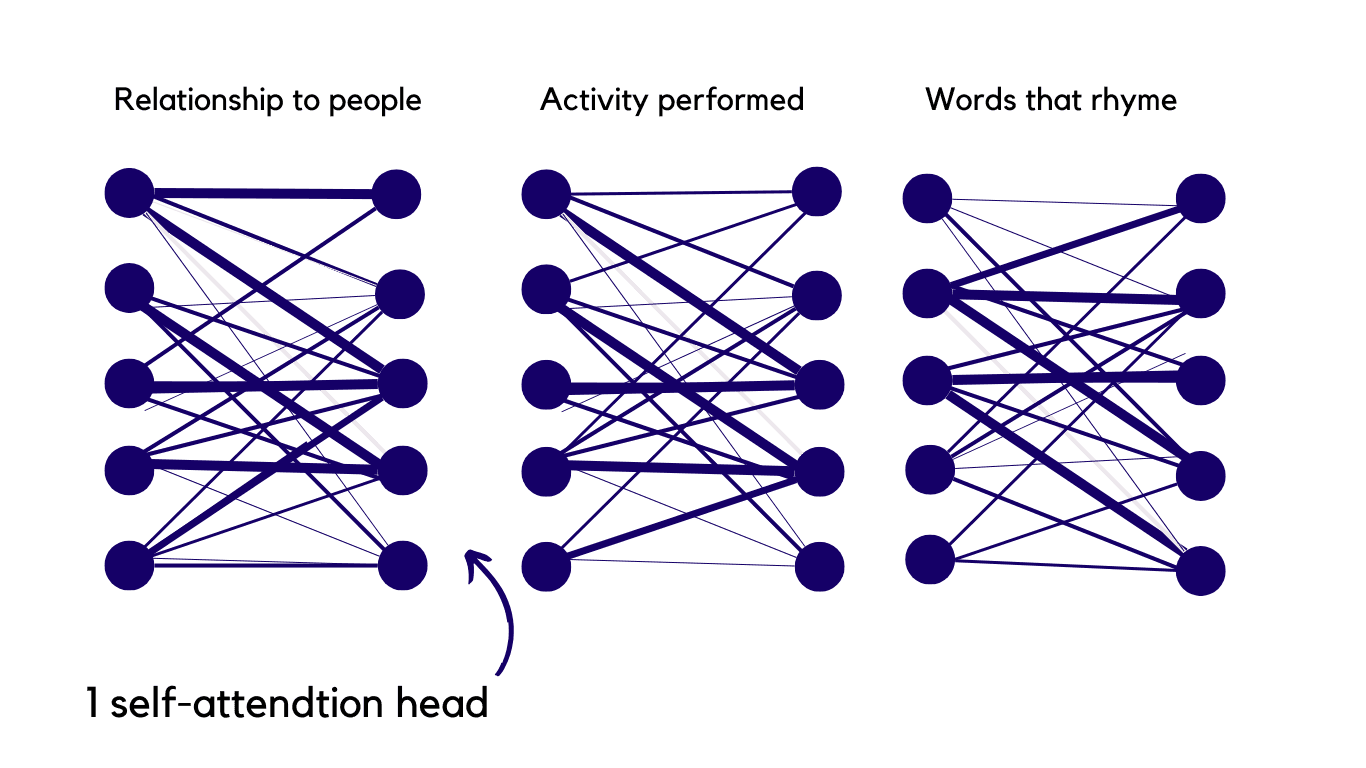
There are many layers of self attention heads used within the model (approximately 12-100) The Ai comes up with new attention heads as new patterns are recognised. further strengthening it's understanding of language.
Step 5: Feed forward Network
it then assigns each word a numerical score which can help it to go on to predict the next word in the sentence, using the attention heads data. It will use every token word in it's internal dictionary to identify the best score (or logit) in real time.
All these score come together to create a vector of logits ie a lot of numbers that are proportional to the probability of the next word could be chosen.
Step 6: Softmax output and de-tokenisation
These numerical scores are then fed into a mathematical model called Softmax which converts them into probabilities with a range between 0-1. This assigns a numerical probability prediction to all of the possible next words.
The word with the highest probability is then chosen as the prediction.
Using de-tokenisation, this number is then converted back into it's token ID form and once again converted back into it's original associated word.
Steps 2-6 are repeated to predict every next word.
Resources
Token ID generator
Attention is all you need research paper that started chat gpt
A detailed youtube video
My favourite AI platforms
- Perplexity - for research + writing tasks this is my go-to
- Merlin - chrome plug-in for summarising
- Gamma AI - Presentations and slide decks
- Chat GTP - for creating my own bots
- AIPRM - for prompt ideas
Learn AI
This article takes you through my experience with learning how to use different AI tools. Detailing how the project started, my experience with it and the surprising transferable skills gained.
Key Summary
AI and quantum computing are set to reshape our world, similar to how the internet did. Learning these skills now really can give you a significant advantage in the job market and in developing new ideas.
Key AI concepts like Machine Learning, Large Language Models, and Natural Language Processing are all linked.
The training process for Large Language Models like ChatGPT involves massive
datasets, parameter adjustments, and iterative improvements, leading to increasingly efficient and accurate language processing.The Transformer architecture, which powers ChatGPT, uses mechanisms like tokenisation, embedding, and self-attention layers to understand and generate human-like text
It understands the relationship between words but also it's place within a sentence which
There are various AI tools available such as Perplexity for research, Merlin for summarising, and ChatGPT for creating bots.
How the project started
AI has become a bit of a buzz word in recent times. It seems that all companies are pivoting to release new AI assisted features at a rate no one could foresee. But what is AI and how can you use it? I'm of the belief that AI and quantum will be the two next major technological advancements that will reshape the wold as we know it. Similar to the creation of the internet, If you are ahead of the curve and can learn these skills you will have a significant advantage both in the job market but also in creation of new ideas.
AI Glossary
When talking about AI there are a few other terms that also come up. Before jumping in, it's important to understand their differences and how they overlap:
Artificial Intelligence (AI): is the field of computer science focused on creating systems that can perform tasks typically requiring human intelligence. It encompasses various approaches to simulate cognitive functions like learning, problem-solving, and decision-making.
Machine Learning: A subset of AI that enables systems to learn and improve from experience without explicit programming. ML algorithms use statistical techniques to find patterns in data and make predictions or decisions.
Large Language Models: Advanced AI systems trained on vast amounts of text data to understand and generate human-like language. They can perform a wide range of language tasks, from translation to text generation. Chat GTP is an example of this.
Generative AI: AI systems capable of creating new content, such as images, text, or music, based on patterns learned from training data. These models can produce original outputs that mimic human-created content.
Quantum Computing: A computing paradigm that leverages quantum mechanical phenomena to perform certain calculations exponentially faster than classical computers. It has the potential to revolutionise fields such as cryptography (code breaking) and complex system simulations (virtual + safe 'what if' scenarios) .
Natural Language Processing (NLP): A branch of AI focused on enabling computers to understand, interpret, and generate human language. NLP powers applications like machine translation, sentiment analysis, and chatbots.
Automation: The use of technology to perform tasks with minimal human intervention. It often involves AI and machine learning to improve efficiency, accuracy, and scalability in various processes and industries.
Open AI: is a parent research organisation that develops open source technologies (ie the code can be adapted/ used by anyone) to advance artificial intelligence in a safe way. Chat GPT is a product that was developed by Open AI, to generate human like text in response to prompts.
Neural Network: In computer terms this is a machine learning system that allows data and information to be processed to solve complex problems. It does this through pattern recognition, decision making and learning from feedback.
The first hurdle of this project, where to begin? There are so many use cases, it's difficult to whittle down what's actually useful and what will be redundant soon.
What is AI?
The field of Artificial intelligence (AI) came about as a way to process complex datasets and solve problems quicker. This newly found capability of machines, particularly computer systems, to perform tasks that would have typically required human intelligence is what we now deem to be AI.
In recent years, ChatGPT has become synonymous with the term AI. This advanced large language model (LLM) was developed by OpenAI one of the largest and well funded research organisations.
ChatGPT is built upon a specific advanced neural network architecture called the transformer architecture, which is a specialised for processing sequential data, such as text.
Advanced Neuronal Networks (ANN)
By using a similar way to how we process information in the brain, whereby synapses transfer information from one neuron to another. Chat GPT uses a digital version of this called an Advanced Neuronal Network (ANN)
The input layer is the raw data that enters the system from the outside world and then linked by the weighted connections which also contain a parameter value, which indicates to the computer how closely a words meaning (or semantic value) is to the other.
The darker the blue the more negative the number and the more purple the more positive the number.
Using this system you can solve a lot of complex problems.
It's essentially the basis of deep learning as it allows the computer to also learn from it's surroundings, as it independently assigns weight and meaning to different words + structures in a way similar to the human brain.
Advanced Neural Network
The larger the dataset is (input layer) the larger the memory is needed to access all the information. Each new release of Chat GPT has a vast increase in the amount of data used to train it which is why it can be seen as more intelligent. It's intelligence is directly proportional to the number of parameters ie connections between the nodes (often also referred to as edges) .
How to train a large language model (LLM)
Step 1: Input data such as text form the internet, books and songs etc is added to the system. For example:
The cat sat on the mat.
Step 2: The LLM is set with initial random parameters which has an assigned value. In this example they are all set to 1, There are billions if not trillions of different parameters:
Parameter 1 = 1
Parameter 2 = 1
Parameter 3 = 1
etc
Step 3: The model guesses the next word (also known as a token)
❌ The cat sat on the apple.
❌ The cat sat on the door.
✅ The cat sat on the mat.
Step 4: The model then calculates the word it predicted and the one it should have predicted, mathematically quantifying what the most effective guess would have been probabilistically.
Step 5: Using this information it then auto-adjusts the parameters so that next time the word is used in that context it will be even more precise meaning the model gets progressively more efficient.
Parameter 1 = 1.6
Parameter 2 = -53
Parameter 3 = 1
Chat GPT
The GPT part stands for Generative pre trainer transformer. To most, like me, this probably won't mean much so let's break it down:
Generative: it's intended output is to generate new content ie. text, image, audio etc
Pre-trained: The AI model was previously trained on data
Transformer: This is the architecture in which the data is processed by to create the new generative content
The Transformer:
This diagram takes us through the the steps of a transformer and explains how the 'intelligence' is actualised. This was the biggest breakthrough in making chat GPT possible.
I'll break down the concept from bottom to top.
The transformer sits between 2 layers, tokenisation and de-tokenisation.
Step 1: Tokenisation
All forms of a word are first assigned a unique number called a Token ID. This means that the mathematical computer model can understand and interpret the data in a numerical form.
Did you know For each grammatical variation of a word (ie apostrophes and capital letters) a new token will assigned.
Once a word has been assigned it's token ID it's static and that number will be used to represent that word from that point onwards.
So using my example from above the token IDs would be:
Step 2: Embedding
It's now time to convert the token IDs into a high-dimensional vector. This numerical fingerprint allows the number to be plotted. We use the term high-dimensional as there are many hundreds of dimensions ( +co-ordinates) that attribute to each word to it's place in space. As humans this far supersedes our maximum 3D conception of what space is, so these numbers can only truly be mapped by a computer.
In creating these vectors Chat GPT can now understand the way in which words relate to each other. For example; Fish and fisherman are more related in meaning than ball and wind. These fixed coordinates help to indicate strong semantic similarities depending on how closely the words sit to each other. By subtracting the coordinates/ vectors of each word you then get given a figure. This indicates how similar these two words are. Allowing the computer to mathematically understand our language.
Step 3: Positional embedding (PE)
So like token embedding which recognises how close a word is in semantic meaning to one another, positional embedding takes a look at the wider sentence structure. Using form fancy maths it can identify where each word in a prompt sits, relative to all of the other words. Which allows it to understand context.
By understanding the position of the word and the context the translation process is much more precise than out previous attempts at direct language translations (ie Greek to English) .
Final Input embedding:
This is the sum of the token embedding and the positional embedding. These are then fed into the self-attention layer.
Step 4: Self attention layer
This layer assigns a numerical weight to each word, relative to how it relates to every other word. So in the example below The and cat have the heaviest weighted line as 'The' is the proposition to 'cat' therefore a strong connection is shown,
This doesn't just happen once it happens multiple times using different parameters ie. words that rhyme, parameters based on activities performed, peoples relationships etc etc.
There are many layers of self attention heads used within the model (approximately 12-100) The Ai comes up with new attention heads as new patterns are recognised. further strengthening it's understanding of language.
Step 5: Feed forward Network
it then assigns each word a numerical score which can help it to go on to predict the next word in the sentence, using the attention heads data. It will use every token word in it's internal dictionary to identify the best score (or logit) in real time.
All these score come together to create a vector of logits ie a lot of numbers that are proportional to the probability of the next word could be chosen.
Step 6: Softmax output and de-tokenisation
These numerical scores are then fed into a mathematical model called Softmax which converts them into probabilities with a range between 0-1. This assigns a numerical probability prediction to all of the possible next words.
The word with the highest probability is then chosen as the prediction.
Using de-tokenisation, this number is then converted back into it's token ID form and once again converted back into it's original associated word.
Steps 2-6 are repeated to predict every next word.
Resources
Token ID generator
Attention is all you need research paper that started chat gpt
A detailed youtube video
My favourite AI platforms
- Perplexity - for research + writing tasks this is my go-to
- Merlin - chrome plug-in for summarising
- Gamma AI - Presentations and slide decks
- Chat GTP - for creating my own bots
- AIPRM - for prompt ideas
Join the Newsletter
Where curiosity meets action!
Each month, you'll receive the latest projects, insights, and resources to empower you to embark on your own learning adventure.
